DANN
Domain Adaption
主要目的:
想想一个分类任务,假设现在我们手中有源域数据和目标域数据。其中源域数据是丰富并且有标记的,而目标域数据是充足的但是没有标记的,但是源域和目标域的特征空间和标记空间相同。很显然,我们可以利用源域数据建立一个分类器,但是由于目标域数据本身没有标记,那么我们无法通过常规方法为目标域构建分类器,这时候就需要用到Domain Adaption了:
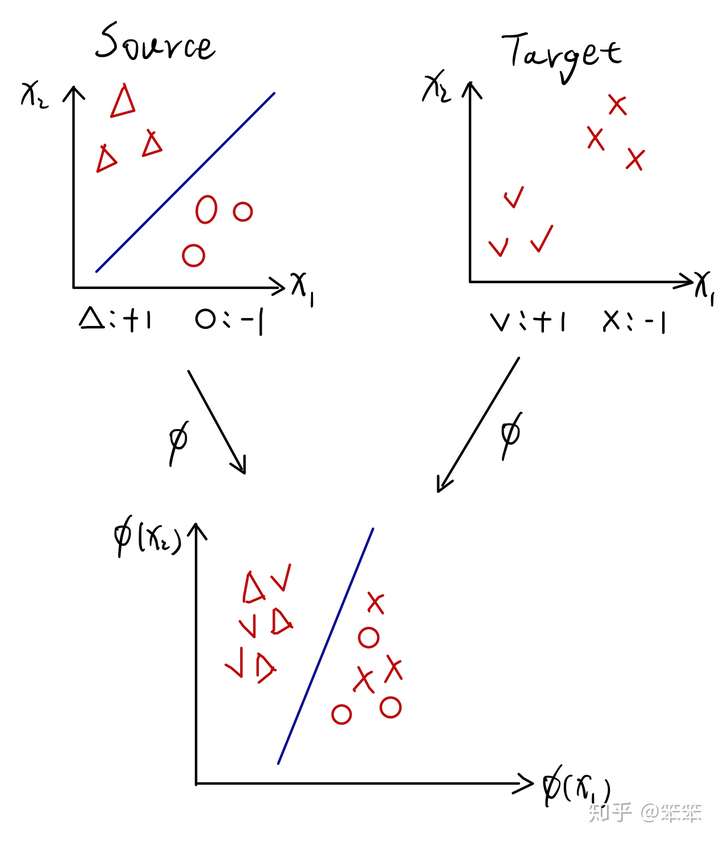
Domain Adaptation的思想就是通过消除源域和目标域的分布差异,使得源域数据和目标域数据能同时被分开。
DANN(Domain-Adaptation Training of Neural Networks)
DANN的应用背景:
源域数据充足并且有标记,目标域数据充足但是无标记,源域和目标域的特征空间和标记空间相同,任务是借助源域数据对目标域数据进行分类
DANN结构:
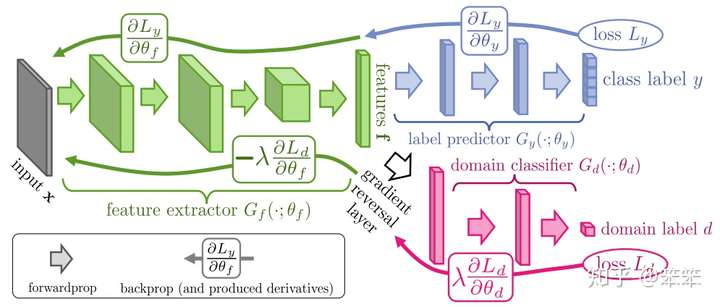
网络分为三部分:
- Feature extractor(特征提取器)
- 提取后续网络后续完成任务所需要的特征
- 将源域样本和目标域样本进行映射和混合
- Label extractoe(域分类器)
- 利用Feature extractor提取的信息对样本进行分类
- Domain classifier(域分类器)
- 判断feature extractor提取的信息来自源域还是目标域
特征提取器提取的信息会传入域分类器,之后域分类器会判断传入的信息到底是来自于源域还是目标域,并计算损失。在反向传播更新参数的过程中,域分类器和特征提取器中间有一个梯度翻转层,也就是说域分类器的训练目标是尽量将输入的信息分到正确的域类别(源域还是目标域),而特征提取与的训练目的恰恰相反(由于梯度翻转层的存在),特征提取器所提取的特征(或者说映射的结果)目的是使域判别器不能正确的判断出信息是来自哪一个域,因此形成一种对抗关系。课件,当域分类器不能将接受的信息正确分为源域样本还是目标域样本时,特征提取器的任务就圆满完成了,因为此时源域样本和目标域样本在某个空间中已经被混合在一起不能分开了。
但是,我们最终的目的是对目标域样本进行分类,那么我们如何保证特征提取器提取的信息是能够用来分类的呢?加入无论输入什么样本给特征提取器,它都输出一个单位向量,这样依旧可以”骗过“域分类器,但是却无法完成后续的分类工作。
这个时候就需要靠Label predictor(类别预测期),因为源域样本是有标记的,所以在提取特征时不仅仅要考虑后面的域判别器的情况,还要利用源域的带标记样本进行有监督训练从而兼顾分类的准确性。
综上,当把特征提取器、域分类器和类别预测器都训练完成后,就可以做到把源域和目标域混合在一起并进行分类了:
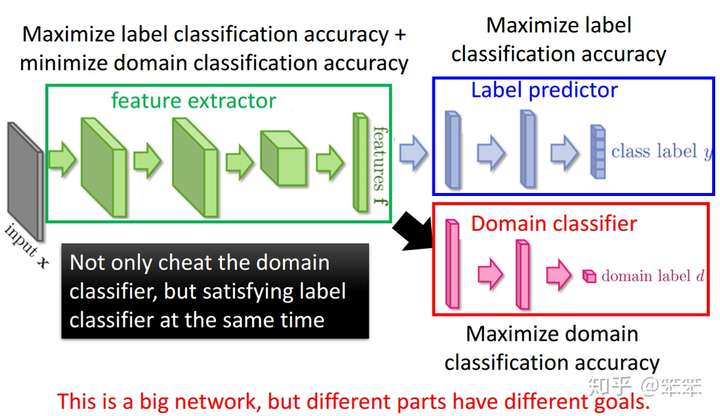
所以,最后得到的损失函数是长介个样子的:
那么怎么理解这个损失函数呢?
实际上前半部分就是label predictor的损失函数,因为我们需要实现迁移之后,仍然能够提取出能区分不同类之间的特征,所以需要最小化label predictor的损失
后半部分就是domain classifier的损失,但是前面有一个的超参数,因为我们实际上需要这个特征提取器提取出来的特征是与对领域特征不敏感的特征,所以需要最大化这个损失,即使这个domain classifier分辨不出来是属于哪一个域的。为了使这两个损失函数同一,所以,我们需要添加一个梯度翻转层,用来取反
最后,将这两项参数相加,最后取最小值就是我们的目标啦!❤