UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS(DCGAN的非监督表征学习)
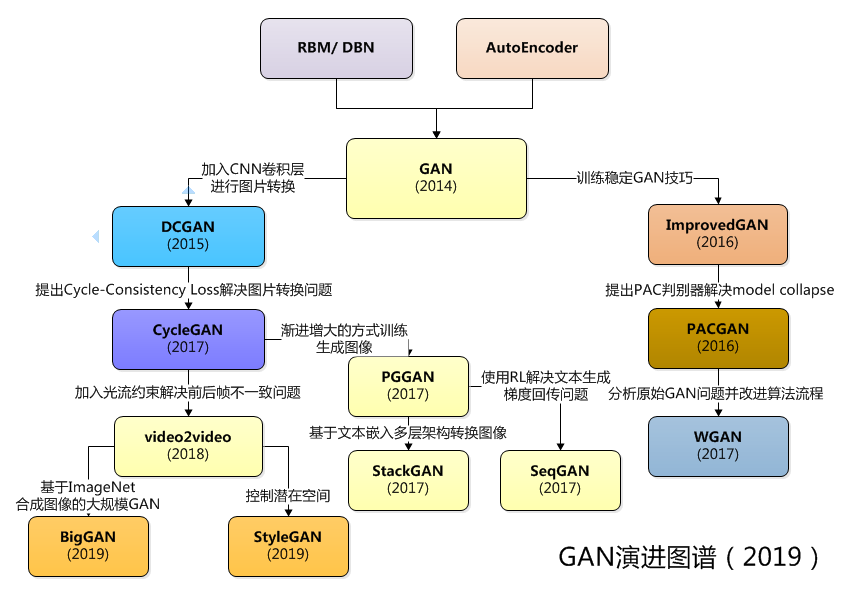
GAN:对抗生成网络,是生成模型的一种,而它的训练则是处于一种对抗博弈状态中的。
GAN的基本结构
GAN的主要结构包括一个生成器G(Generator)和一个判别器(Discriminator)
关于生成器
对于生成器,输入需要一个n维度向量,输出为图片像素大小的图片。因此需要得到输入的向量。
关于判别器
输入为图片,输出为图片的真伪标签
如何训练
基本流程如下:
-
初始化判别器D的参数和生成器G的参数
-
从真实样本中采样个样本,从先验分布噪声中采样个噪声样本并通过生成器获取个生成样本。固定生成器G,训练判别器D尽可能好地准确判别真实样本和生成样本,尽可能大地区分正确样本和生成的样本。
-
循环次更新判别器之后,使用较小的学习率来更新一次生成器的参数,训练生成器使其尽可能能够减小生成样本与真实样本之间的差距,也相当于尽量使得判别器判别错误
-
多次更新迭代之后,最终理想情况是使得判别器判别不出样本来自生成器的输出还是真实的输出,亦即最终样本判别概率均为0.5
Tips:之所以要训练k次判别器,再训练生成器,是因为要现拥有一个好的判别器,使得能够较好地区分出真实样本和生成样本之后,才能更为准确地对生成器进行更新
训练相关理论基础
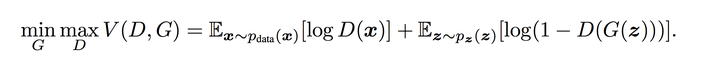
判别器在这里是一种分类器,用于区分样本的真伪,因此我们常常使用交叉熵(cross entropy)来进行判别分布的相似性,交叉熵公式如下图所示:
Tips:公式中的pi和qi为真实的样本分布和生成器的样本分布。
在当前模型的情况下,判别器为一个二分类问题,因此可以对基本交叉熵进行更具体地展开:
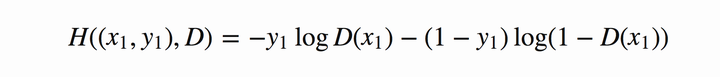
Tips: 其中,假定y1为正确样本分布,那么对应的(1-y1))就是生成样本的分布。D表示判别器,则D(x1)表示判别样本为正确的概率,(1-D(x1)))则对应着判别为错误样本的概率。这里仅仅是对当前情况下的交叉熵损失的具体化。相信大家也还是比较熟悉。
将上式推广到N个样本后,将N个样本相加得到对应的公式如下:
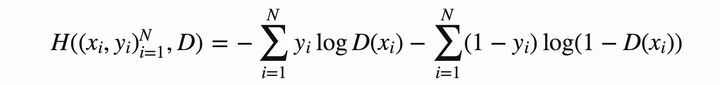
下面加入GAN中特殊的地方:
对于GAN中的样本点 ,对应于两个出处,要么来自于真实样本,要么来自于生成器生成的样本
~
( 这里的
是服从于投到生成器中噪声的分布)。
其中,对于来自于真实的样本,我们要判别为正确的分布 。来自于生成的样本我们要判别其为错误分布(
)。将上面式子进一步使用概率分布的期望形式写出(为了表达无限的样本情况,相当于无限样本求和情况),并且让
为 1/2 且使用
表示生成样本可以得到如下图8的公式:
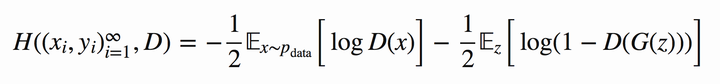
实际上就是原本的 公式,发现他们是不是其实就是同一个东西呢!😄
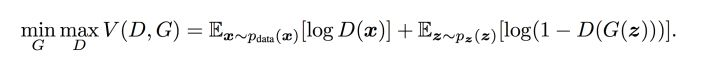
-
这里的
相当于表示真实样本和生成样本的差异程度。
-
先看
。这里的意思是固定生成器G,尽可能地让判别器能够最大化地判别出样本来自于真实数据还是生成的数据。
-
再将后面部分看成一个整体令
=
,这里是在固定判别器D的条件下得到生成器G,这个G要求能够最小化真实样本与生成样本的差异。
-
通过上述min max的博弈过程,理想情况下会收敛于生成分布拟合于真实分布。
DCGAN
对现行CNN架构三个改进的学习和纠正
-
所有的卷积网络,凡是自卷积开始,使用了确定性pooling函数的,都能学习到自己空间上的降采样。我们在生成器中使用了这种方法,允许生成器学习到它自己的空间降采样,也包括判别器
-
消除卷积特征顶部的全连接层:全局pooling增强了模型的稳定性,但减缓了收敛速度。将最该层的卷积特征和输入连接起来,生成器和判别器各自做自己的输出。
-
不使用BN。将每一层的输入都正则化为期望0方差1。改进了训练问题,也缓解了深层网络中的梯度溢出问题。但实际上,在这种方法在深层的生成器中被证明是不适用的,它会导致生成器反复震荡生成单点数据,这在GANs中往往是失败的。对于直接将BN使用在所有层上的方法,同样会引起震荡并导致模型不稳定,所以,不要再生成器的输入层上使用BN,也不要在判别器的输出层上使用BN
DCGAN的架构指导:
- 在判别器中,使用带步长的卷积层来替换所有pooling层,生成器中使用小步长卷积来代替pooling层
- 在生成器和判别器中使用BN(有效的使数据服从某个固定的数据分布)
- 去除深度架构中的全连接层(因为全连接层的参数过多,容易使网络过拟合)
- 生成器中,除去最后一层使用Tanh,每一层都使用ReLU来激活(因为发现有边界的激活函数可以让模型更快的学习,并且能快速的覆盖彩色空间)
- 判别器中,每一层都用LeakReLU来激活(激活函数的作用是为了在神经网络中进行非线性变换,在DCGAN中,生成器和判别器使用不同的激活函数。)