物体检测
1. 物体检测与图片分类的不同点:
- 图片分类器通常只需要输出对图片中的主物体的分类。但物体检测必须能够识别多个物体,即使有些物体可能在图片中不是占主要版面。严格来讲,这个任务一般叫多类物体检测,但绝大部分研究都是针对多类的设置,这里为了简单去掉了“多类”。
- 图片分类器只需要输出将图片识别成某类的概率,但物体检测不仅需要输出识别的概率,还需要识别物体在图片中的位置。这个通常是一个括住这个物体的方框,通常也被称之为边界框(bounding box)
2. 基于卷积神经网络的物体检测算法
-
RCNN https://arxiv.org/abs/1311.2524
-
Fast R-CNN https://arxiv.org/abs/1504.08083
-
Faster R-CNN https://arxiv.org/abs/1506.01497
-
Mask R-CNN https://arxiv.org/abs/1703.06870
-
SSD https://arxiv.org/abs/1512.02325
-
YOLO https://arxiv.org/abs/1506.02640
-
YOLOv2 https://arxiv.org/abs/1612.08242
3. 具体介绍
3.1 R-CNN(区域卷积神经网络)
这是一个基于卷积神经网络的物体检测的奠基之作。其核心思想是在对每张图片选取多个区域,然后每个区域作为一个样本进入一个卷积神经网络来抽取特征,最后使用分类器来对其进行分类,和一个回归器来得到准确的边框。

具体来说,这个算法有如下几个步骤:
- 对每张输入图片使用一个基于规则的“选择型搜索”算法来选取多候选区域
- 跟微调迁移学习里那样,选取一个预先训练好的神经网络并去掉最后一个输入层。每个区域被调整成整个网络要求的输入大小并计算输出。这个输出将作为这个区域的特征。
- 使用这些区域特征训练多个SVM来做物体识别,每个SVM预测一个区域是不是包含某个物体
- 使用这些区域特征来训练线性回归器将候选区域
直观上R-CNN很好理解,但问题是它可能特别慢。一张图片我们可能选出上千个区域,导致一张图片需要做上千次预测。虽然跟微调不一样,这里训练可以不用更新用来抽特征的卷积神经网络,从而我们可以事先算好每个区域的特征并保存。但对于预测,我们无法避免这个。从而导致R-CNN很难在十几种被使用
3.2 Fast R-CNN(快速的区域卷积神经网络)
Fast-RCNN对R-CNN主要做了两点改进来提升性能
- 考虑到R-CNN里面的大量区域可能是相互覆盖,每次重新抽取特征过于浪费。因此Fast R-CNN先对输入图片抽取特征,然后再选取区域
- 代替R-CNN使用多个SVM来做分类,Fast-RCNN使用单个多类逻辑回归,这也是前面教程里默认使用的

从示意图中可以看到,使用选择型搜索选取的区域是作用在卷积神经网络提取的特征上。这样我们只需要对原始的输入图片做一次特征提取即可,如此节省了大量重复计算。
Fast R-CNN提出特征区域池化层(Region of Interest(RoI) Pooling),它的输入为特征和一系列的区域,对每个区域它将其均匀划分成n * m的小区域,并对每个小区域做最大池化,从而得到一个n * m的输出。因此不管输入区域的大小,RoI池化层都将其池化成固定大小输出。
下面,详细的来看一下ROI Pooling:
ROIs Pooling顾名思义,是Pooling层的一种,而且是针对RoIs的Pooling,它的特点是输入特征图尺寸不固定,但是输出特征图尺寸固定。
- 在Fast R-CNN中,RoI是指Selective Search完成后得到的“候选框”在特征图上的映射,如下图所示
- 在Faster R-CNN中,候选框是经过RPN产生的,然后再把各个“候选框”映射到特征图上,得到RoIs
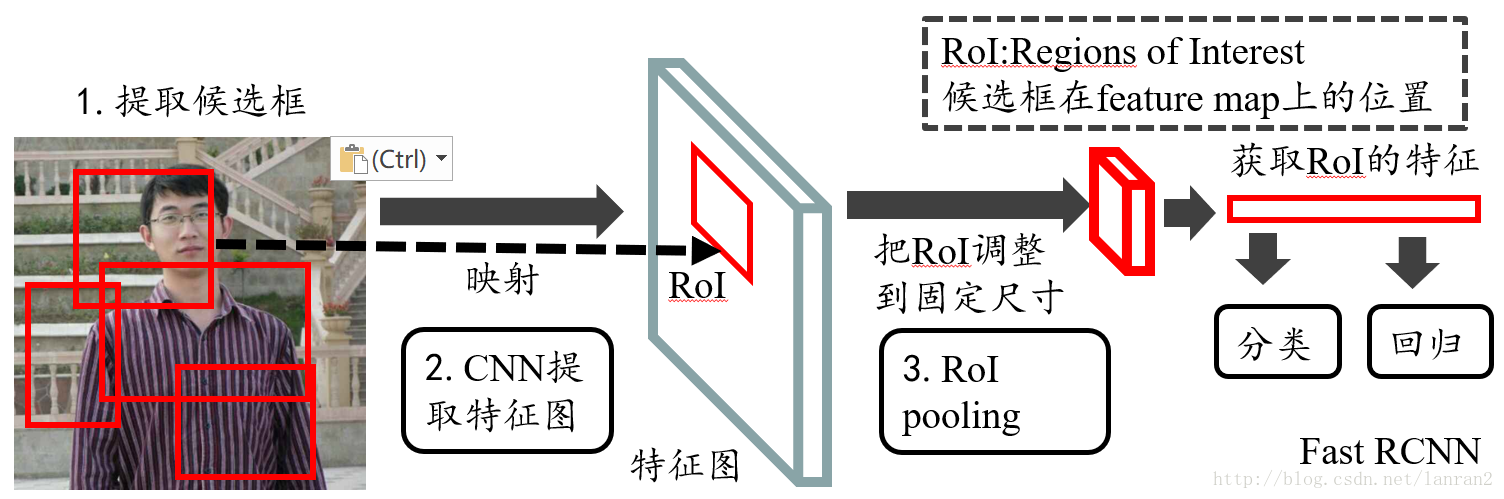
图1 Fast R-CNN整体结构
ROI Pooling的输入:
- **特征图:**指的是图1中所示的特征图,在Fast R-CNN中,它位于RoI Pooling之前,在Faster RCNN中,它是与RPN共享的那个特征图,通常我们称之为“share_conv”
- rois:在Fast R-CNN中,指的是Selective Search的输出;在Faster R-CNN中指的是RPN的输出,一堆矩形候选框框,形状为1 * 5 * 1 * 1 (4个坐标+索引index),其中值得注意的是:坐标的参考系不是针对feature map这张图的,而是针对原图的(神经网络最开始的输入)
ROI Pooling的输出:
输出是batch个vector,其中batch的值等于RoI的个数,vector的大小为channel * w * h;RoI Pooling的过程就是将一个个大小不同的box矩形框,都映射成大小固定(w * h)的矩形框
ROI Pooling的过程:
- 根据输入image,将RoI映射到feature map对应位置
- 将映射后的区域划分为相同大小的sections(sections数量与输出的维度相同)
- 对每个sections进行max pooling操作
这样我们就可以从不同大小的方框得到固定大小的相应的feature maps。值得一提的是,输出的feature maps的大小不取决与ROI和卷积feature maps的大小。ROI Pooling最大的好处就在于极大地提高了处理速度
Example:
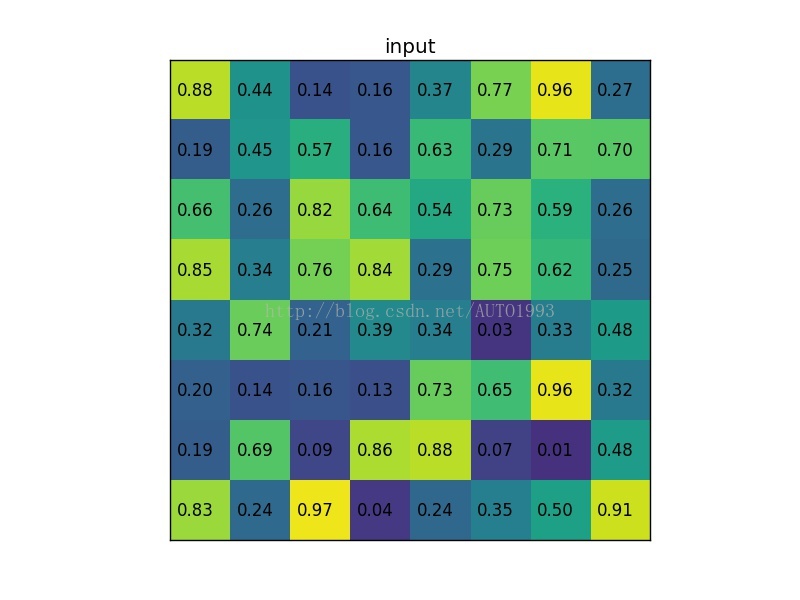
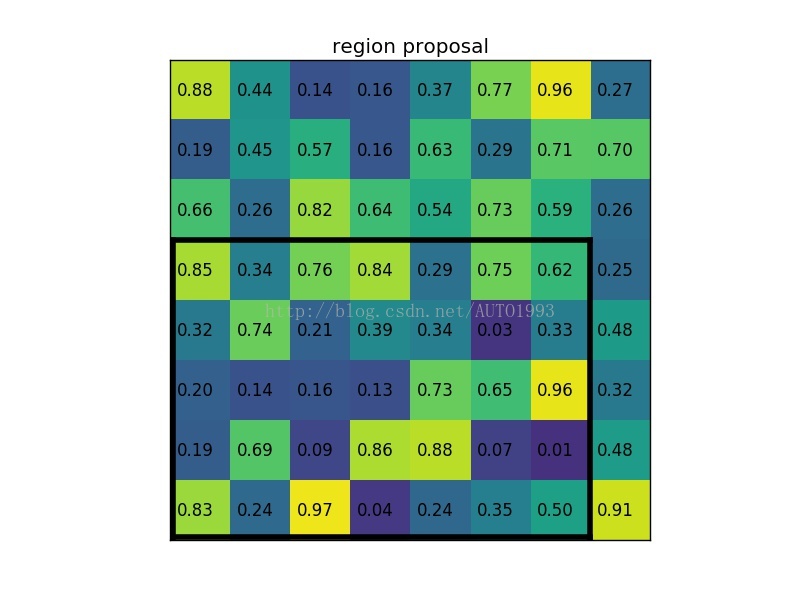
考虑一个8 * 8大小的feature map,一个ROI,以及输出大小为2 * 2
1)输入固定大小的feature map
2)region proposal投影之后位置(左上角,右下角坐标):(0,3),(7,8)
3)将其划分为(2 * 2)个sections(因为输出大小为2 * 2),我们可以得到:
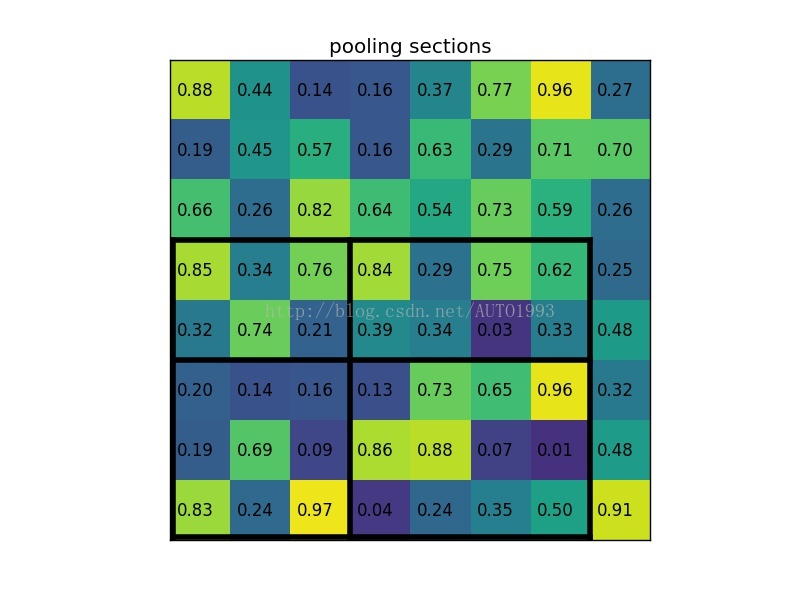
4)对每个section做max pooling,可以得到
Faster R-CNN
Fast R-CNN沿用了R-CNN的选择型搜索方法来选择区域,这个通常很慢。Faster R-CNN做的主要改进就是提出了**区域候选网络(Region Proposal Network, RPN)**来代替选择型搜索。
它是这么工作的:
- 在输入特征上放置一个填充为1通道是256 的3 * 3卷积。这样,连同他的周围8个像素,都被映射成一个长为256的向量
- 以对每个像素为中心生成数个大小和长宽比预先设计好的k个默认框,通常也叫做锚框
- 对每个边框,使用其中心像素对应的256维向量作为特征,RPN训练一个2类分类器来判断这个区域是不是含有任何感兴趣的物体还是只是背景,和一个4位输出的回归分类器来预测一个更准确的边框
- 对于所有的锚框,个数为n m k,如果输入大小是n * m, 选出被判断成还有物体的,然后对他们对应的回归器预测的边框作为输入放进接下来的RoI池化层
虽然看上去有些复杂,但RPN思想非常直观。首先候选预先配置好的一些区域,然后通过神经网络来判断这些区域是不是感兴趣的。如果是,那么再预测一个更加准确的边框。这样我们能有效降低搜索任何形状的边框的代价。
Faster R-CNN的RPN详解:
-
anchors:特征可以看做一个尺度5139的256通道图像,对于该图像的每一个位置,考虑9个可能的候选窗口:三种面积{128,256,512}×{128,256,512}×三种比例{1:1,1:2,2:1}{1:1,1:2,2:1}。这些候选窗口称为anchors。下图示出5139个anchor中心,以及9种anchor示例。
特征可以看做一个尺度5139的256通道图像,对于该图像的每一个位置,考虑9个可能的候选窗口:三种面积{128,256,512}×{128,256,512}×三种比例{1:1,1:2,2:1}{1:1,1:2,2:1}。这些候选窗口称为anchors。下图示出5139个anchor中心,以及9种anchor示例。

-
SOFTMAX的两支

计算每个像素256-d的9个尺度下的值,得到9个anchor,我们给每个anchor分配一个二进制的标签(前景背景)。我们分配正标签前景给两类anchor:1)与某个ground truth(GT)包围盒有最高的IoU重叠的anchor(也许不到0.7),2)与任意GT包围盒有大于0.7的IoU交叠的anchor。注意到一个GT包围盒可能分配正标签给多个anchor。我们分配负标签(背景)给与所有GT包围盒的IoU比率都低于0.3的anchor。非正非负的anchor对训练目标没有任何作用,由此输出维度为(2*9)18,一共18维。
假设在conv5 feature map中每个点上有k个anchor(默认k=9),而每个anhcor要分foreground和background,所以每个点由256d feature转化为cls=2k scores;而每个anchor都有[x, y, w, h]对应4个偏移量,所以reg=4k coordinates
补充一点,全部anchors拿去训练太多了,训练程序会在合适的anchors中随机选取128个postive anchors+128个negative anchors进行训练。
以上是传统的RPN,下面是Faster R-CNN 的RPN部分。 -
bounding box regression
前2.)中已经计算出foreground anchors,使用bounding box regression回归得到预设anchor-box到ground-truth-box之间的变换参数,即平移(dx和dy)和伸缩参数(dw和dh),由此得到初步确定proposal。
如图9所示绿色框为飞机的Ground Truth(GT),红色为提取的foreground anchors,那么即便红色的框被分类器识别为飞机,但是由于红色的框定位不准,这张图相当于没有正确的检测出飞机。所以我们希望采用一种方法对红色的框进行微调,使得foreground anchors和GT更加接近。

对于窗口一般使用四维向量(x, y, w, h)表示,分别表示窗口的中心点坐标和宽高。对于图 10,红色的框A代表原始的Foreground Anchors,绿色的框G代表目标的GT,我们的目标是寻找一种关系,使得输入原始的anchor A经过映射得到一个跟真实窗口G更接近的回归窗口G’,即:给定A=(Ax, Ay, Aw, Ah),寻找一种映射f,使得f(Ax, Ay, Aw, Ah)=(G’x, G’y, G’w, G’h),其中(G’x, G’y, G’w, G’h)≈(Gx, Gy, Gw, Gh)。

那么经过何种变换才能从图6中的A变为G’呢? 比较简单的思路就是:
-
先做平移

-
再做缩放

观察上面4个公式发现,需要学习的是dx(A),dy(A),dw(A),dh(A)这四个变换。当输入的anchor与GT相差较小时,可以认为这种变换是一种线性变换, 那么就可以用线性回归来建模对窗口进行微调(注意,只有当anchors和GT比较接近时,才能使用线性回归模型,否则就是复杂的非线性问题了)。对应于Faster RCNN原文,平移量(tx, ty)与尺度因子(tw, th)如下:
接下来的问题就是如何通过线性回归获得dx(A),dy(A),dw(A),dh(A)了。线性回归就是给定输入的特征向量X, 学习一组参数W, 使得经过线性回归后的值跟真实值Y(即GT)非常接近,即Y=WX。对于该问题,输入X是一张经过卷积获得的feature map,定义为Φ;同时还有训练传入的GT,即(tx, ty, tw, th)。输出是dx(A),dy(A),dw(A),dh(A)四个变换。那么目标函数可以表示为:
其中Φ(A)是对应anchor的feature map组成的特征向量,w是需要学习的参数,d(A)是得到的预测值(*表示 x,y,w,h,也就是每一个变换对应一个上述目标函数)。为了让预测值(tx, ty, tw, th)与真实值最小,得到损失函数:
函数优化目标为:

-
-
将预proposal利用feat_stride和im_info将anchors映射回原图,判断预proposal是否大范围超过边界,剔除严重超出边界的。
按照softmax score进行从大到小排序,提取前2000个预proposal,对这个2000个进行NMS(非极大值抑制),将得到的再次进行排序,输出300个proposal。







NMS(非极大抑制致)
由于锚点经常重叠,因此候选框最终也会在同一个目标上重叠。为了解决重复候选框的问题,我们使用一个简单的泛,称为非极大抑制(NMS)。NMS获取按照分数排序的候选列表并对已排序的列表进行迭代,丢弃那些IoU值大于某个预定义阈值的候选框,并提出一个具有更高分数的候选框。总之,抑制的过程是一个迭代-遍历-消除的过程,如下图所示:
-
将所有候选框的得分进行排序,选中最高分及其所对应的框


-
遍历其余的框,如果它和当前最高得分框的重叠面积大于一定的阈值,我们将其删除

-
从没有处理的框中继续选择一个得分最高的,重复上述过程。



Mask R-CNN
Mask R-CNN在Faster R-CNN上加入了一个新的像素级别的预测层,它不仅对一个锚框预测它对应的类和真实的边框,而且他会判断这个锚框类每个像素对应的那个物体还是只是背景。后者是语义分割要解决的问题。Mask R-CNN使用了全连接卷积网络(FCN)来完成这个预测。当然这也意味着训练数据必须有像素级别的标注,而不是简单的边框。

因为FCN会精确预测每个像素的类别,就是输入图片中的每个像素都会在标注中对应一个类别。对于输入图片中的一个锚框,我们可以精确的匹配到像素标注中对应的区域。但是PoI池化是作用在卷积之后的特征上,其默认是将锚框做了定点化。例如假设选择的锚框是( x , y , w , h ) ,且特征抽取将图片变小了16倍,就是如果原始图片是256 × 256 ,那么特征大小就是16 × 16 。这时候在特征上对应的锚框就是变成了( ⌊ x / 16 ⌋ , ⌊ y / 16 ⌋ , ⌊ w / 16 ⌋ , ⌊ h / 16 ⌋ ) 。如果x , y , w , h 中有任何一个不被16整除,那么就可能发生错位。同样道理,在上面的样例中我们看到,如果锚框的长宽不被池化大小整除,那么同样会定点化,从而带来错位。
通常这样的错位只是在几个像素之间,对于分类和边框预测影响不大。但对于像素级别的预测,这样的错位可能会带来大问题。Mask R-CNN提出一个RoI Align层,它类似于RoI池化层,但是去除掉了定点化步骤,就是移除了所有⌊ ⋅ ⌋ 。如果计算得到的表框不是刚好在像素之间,那么我们就用四周的像素来线性插值得到这个点上的值。
SSD:单发多框检测器
在R-CNN系列的模型里面。区域候选和分类是分作两块来进行的。SSD则将其统一成一个步骤来使得模型更加简单并且速度更快。
它跟Faster R-CNN主要有两点不一样:
-
对于锚框,我们不再首先判断它是不是含有感兴趣物体,再将正类锚框放入真正物体分类。SSD里我们直接使用一个num_class+1类分类器来判断它对应的是哪类物体,还是只是背景。我们也不再有额外的回归器对边框再进一步预测,而是直接使用单个回归器来预测真实边框。
-
SSD不只是对卷积神经网络输出的特征做预测,它会进一步将特征通过卷积和池化层变小来做预测。这样达到多尺度预测的效果


YOLO:只需要看一遍
不管是Faster R-CNN还是SSD, 他们声称的锚框仍然有大量是重叠的,从而导致仍然有大量的区域被重复计算了。YOLO试图来解决这个问题。它将图片特征均匀的切成S * S块,每一块当做一个锚框。每个锚框预测B个框,以及这个锚框主要包含哪个物体。

YOLO v2:更好,更快,更强
YOLO v2 对WOLO进行一些改进的地方,其主要包括:
-
使用更好的卷积神经网络来做特征提取,使用更大输入图片448 * 448 使得特征输出大小增大到13 * 13
-
不再使用均匀切割的锚框,而是对训练数据里的真实锚框做聚类,然后使用聚类中心作为锚框。相对于SSD 和Faster R-CNN来说可以大幅降低锚框的个数
-
不再使用YOLO的全连接层来预测,而是同SSD一样使用卷积。例如假设使用5个锚框(聚类为5类),那么物体分类使用通道数是 5 * (1 + num_classes)的1 * 1卷积,边框回归使用通道数为4 * 5